Informationen zu Warnungen durch die code scanning
Du kannst die code scanning so konfigurieren, dass der Code in einem Repository mit der CodeQL-Standardanalyse, einer Analyse eines Drittanbieters oder mehreren Arten von Analysen überprüft wird. Nach Abschluss der Analyse werden die daraus resultierenden Warnungen in der Sicherheitsansicht des Repositorys nebeneinander angezeigt. Ergebnisse von Drittanbietertools oder benutzerdefinierten Abfragen enthalten möglicherweise nicht alle Eigenschaften, die in Warnungen der CodeQL-Standardanalyse von GitHub angezeigt werden. Weitere Informationen findest du unter Konfigurieren der code scanning für ein Repository.
Standardmäßig wird dein Code im Standardbranch und bei Pull Requests über das code scanning regelmäßig analysiert. Informationen zur Verwaltung von Warnungen für Pull Requests findest du unter Selektieren von code scanning-Warnungen in Pull Requests.
Informationen zu Warnungsdetails
Bei jeder Warnung werden das Problem mit dem Code und der Name des Tools, das dieses erkannt hat, hervorgehoben. Du kannst die Codezeile anzeigen, die die Warnung ausgelöst hat, sowie Eigenschaften der Warnung (z. B. Warnungsschweregrad, Sicherheitsschweregrad und die Art des Problems). Warnungen informieren dich auch darüber, seit wann das Problem besteht. Bei Warnungen, die von der CodeQL-Analyse identifiziert wurden, werden auch Informationen zur Behebung des Problems angezeigt.
Der Status und die Details auf der Warnungsseite spiegeln nur den Status der Warnung für den Standardbranch des Repositorys wider, auch wenn die Warnung in anderen Branches vorhanden ist. Du kannst den Status der Warnung für nicht standardmäßigen Branches im Abschnitt Betroffene Branches rechts auf der Warnungsseite sehen. Wenn eine Warnung im Standardbranch nicht vorhanden ist, wird der Status der Warnung als „in Pull Request“ oder „in Branch“ in grau angezeigt.
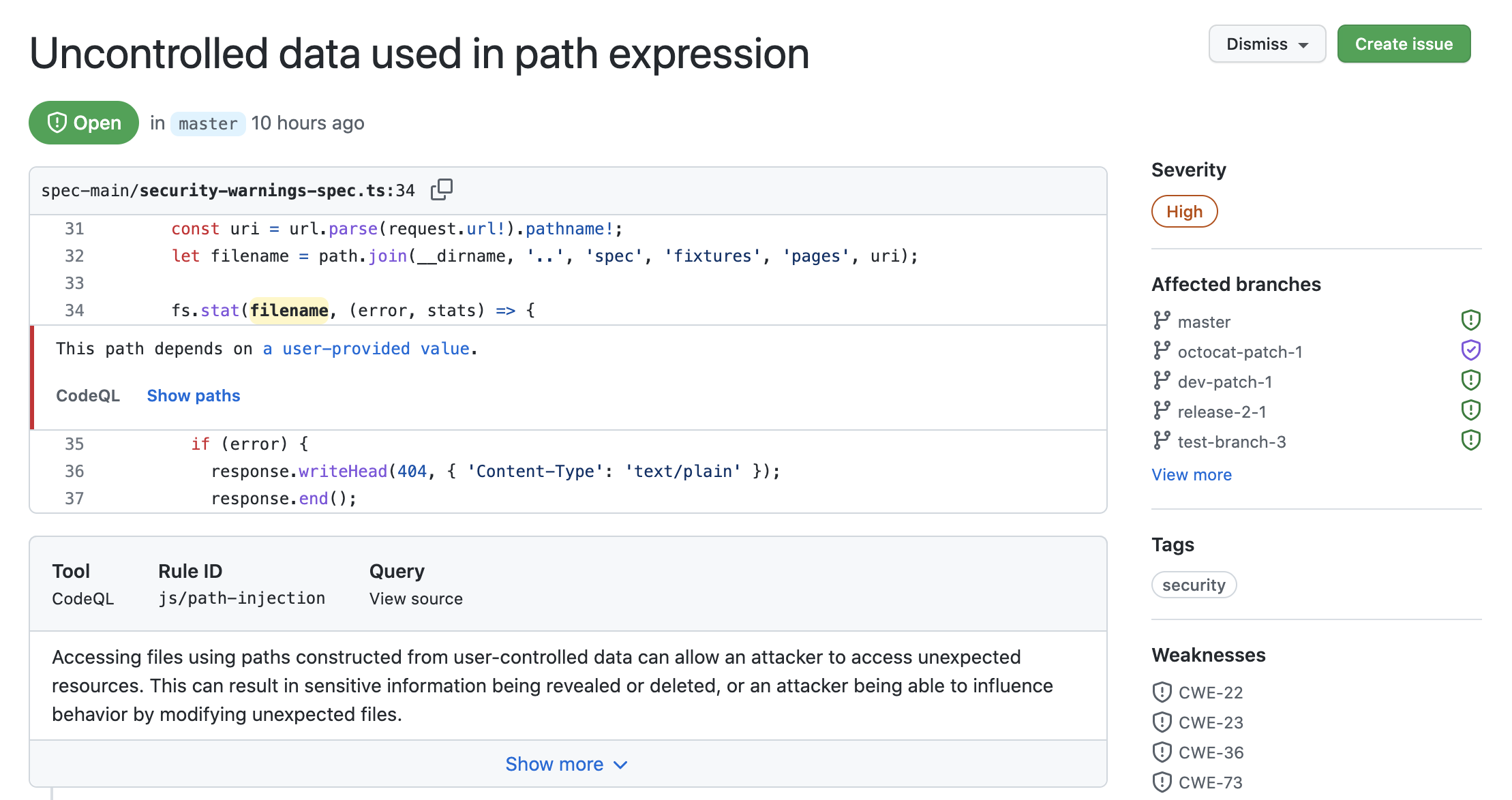
Wenn du die code scanning mit CodeQL konfigurierst, können auch Datenflussprobleme in deinem Code erkannt werden. Die Datenflussanalyse findet potenzielle Sicherheitsprobleme in Code wie die unsichere Verwendung von Daten, die Übergabe gefährlicher Argumente an Funktionen und das Durchsickern vertraulicher Informationen.
Wenn die code scanning Datenflusswarnungen meldet, zeigt GitHub Ihnen, wie die Daten durch den Code fließen. Mit der Code scanning kannst du die Bereiche deines Codes identifizieren, in denen vertrauliche Informationen durchsickern und die einen möglichen Ansatzpunkt für Angriffe böswilliger Benutzer*innen darstellen.
Informationen zu Schweregraden
Mögliche Warnungsschweregrade sind Error, Warning und Note.
Wenn die code scanning als Überprüfung für Pull Requests aktiviert ist, tritt bei der Überprüfung ein Fehler auf, wenn Ergebnisse mit dem Schweregrad error gefunden werden. Du kannst angeben, welcher Schweregrad für Codeüberprüfungswarnungen einen Überprüfungsfehler verursacht. Weitere Informationen findest du unter Anpassen der code scanning.
Informationen zu Sicherheitsschweregraden
Die Code scanning zeigt Sicherheitsschweregrade für Warnungen an, die von Sicherheitsabfragen generiert wurden. Die Sicherheitsschweregrade können Critical, High, Medium oder Low sein.
Für die Berechnung des Sicherheitsschweregrads einer Warnung verwenden wir CVSS-Daten (Common Vulnerability Scoring System). Das CVSS ist ein offenes Framework, über das die Merkmale und Schweregrade von Sicherheitsrisiken bei Software kommuniziert werden und das häufig von anderen Sicherheitsprodukten für die Bewertung von Warnungen verwendet wird. Weitere Informationen dazu, wie Schweregrade berechnet werden, findest du in diesem Blogbeitrag.
Standardmäßig führen alle Ergebnisse der code scanning mit einem Sicherheitsschweregrad von Critical oder High dazu, dass bei der Überprüfung ein Fehler auftritt. Du kannst angeben, welcher Sicherheitsschweregrad bei Ergebnissen der code scanning zu einem Fehler bei der Überprüfung führen soll. Weitere Informationen findest du unter Anpassen der code scanning.
Informationen zu Analyseursprüngen
Du kannst für ein Repository mehrere Konfigurationen für Codeanalysen mit verschiedenen Tools sowie für verschiedene Sprachen oder Bereiche des Codes ausführen. Jede Konfiguration der Codeüberprüfung ist der Analyseursprung für alle von ihr generierten Warnungen. So verfügt beispielsweise eine mithilfe der CodeQL-Standardanalyse mit GitHub Actions generierte Warnung über einen anderen Analyseursprung als eine extern generierte Warnung, die über die Codeüberprüfungs-API hochgeladen wurde.
Wenn du mehrere Konfigurationen zum Analysieren einer Datei verwendest, werden alle im Rahmen einer einzelnen Abfrage erkannten Probleme als Warnungen mit verschiedenen Analyseursprüngen gemeldet. Wenn eine Warnung über mehr als einen Analyseursprung verfügt, wird das Symbol neben allen relevanten Branches im Abschnitt Betroffene Branches rechts auf der Warnungsseite angezeigt. Du kannst auf das Symbol zeigen, um die Namen der einzelnen Analyseursprünge und den Status der Warnung für den jeweiligen Analyseursprung anzuzeigen. Darüber hinaus kannst du auf der Zeitachse auf der Warnungsseite anzeigen, seit wann die Warnungen für die einzelnen Analyseursprünge jeweils vorliegen. Wenn eine Warnung über nur einen Analyseursprung verfügt, werden auf der Warnungsseite keine Informationen zu Analyseursprüngen angezeigt.
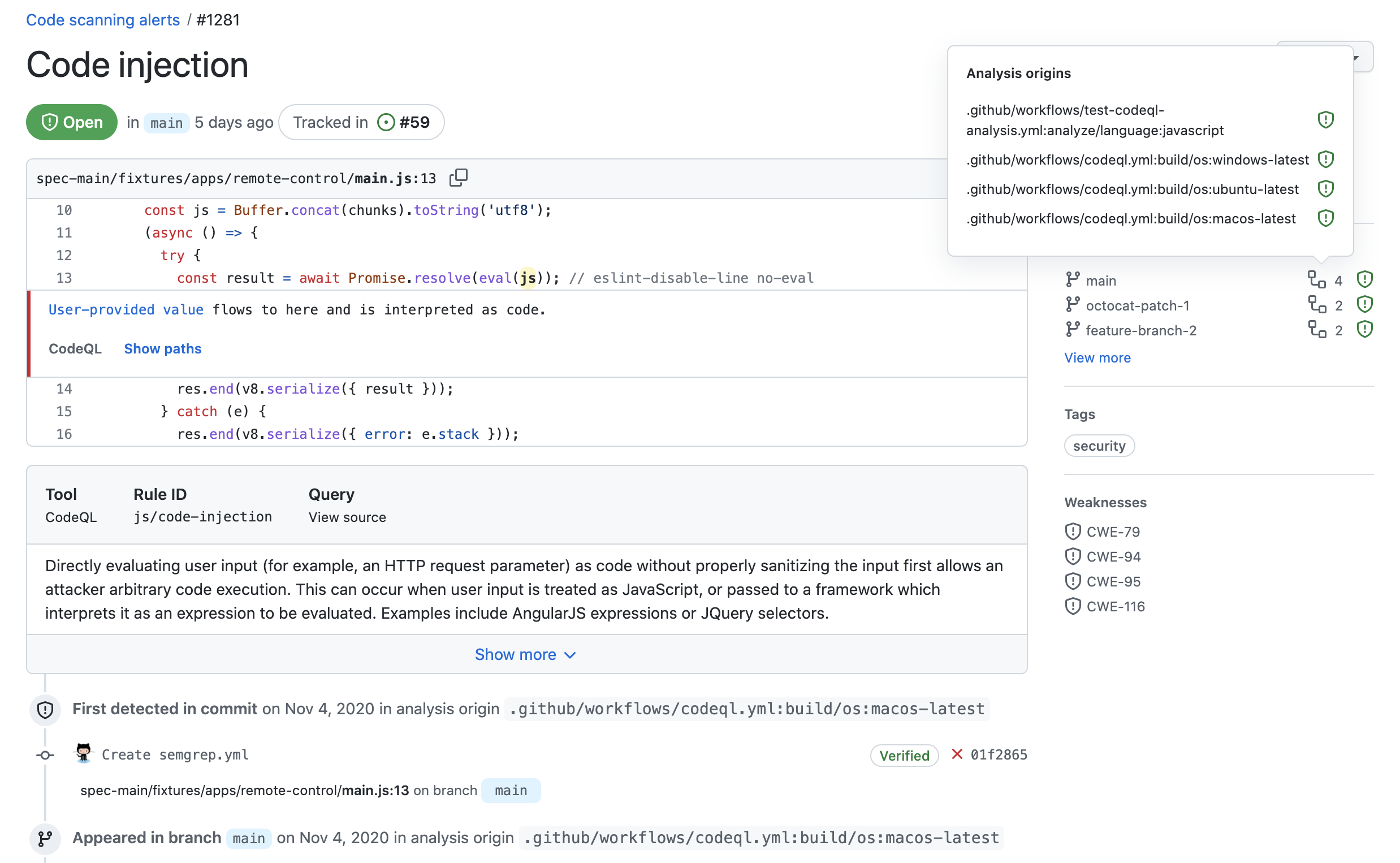
Hinweis: Manchmal werden Codeüberprüfungswarnungen bei einem Analyseursprung als behoben angezeigt, bei einem anderen Analyseursprung jedoch noch als offen. Dieses Problem kannst du beheben, indem du die zweite Codeüberprüfungskonfiguration erneut ausführst, um den Warnungsstatus für diesen Analyseursprung zu aktualisieren.
Informationen zu Kennzeichnungen für nicht in Anwendungscode gefundene Warnungen
GitHub weist Warnungen, die nicht in Anwendungscode gefunden wurden, eine Kategoriekennzeichnung zu. Mit dieser Kennzeichnung wird angegeben, wo die Warnung gefunden wurde.
- Generiert: Vom Buildprozess generierter Code
- Test: Testcode
- Bibliothek: Bibliotheks- oder Drittanbietercode
- Dokumentation: Dokumentation
Bei der Code scanning werden die Dateien basierend auf dem Dateipfad den Kategorien zugeordnet. Ein manuelles Kategorisieren von Quelldateien ist nicht möglich.
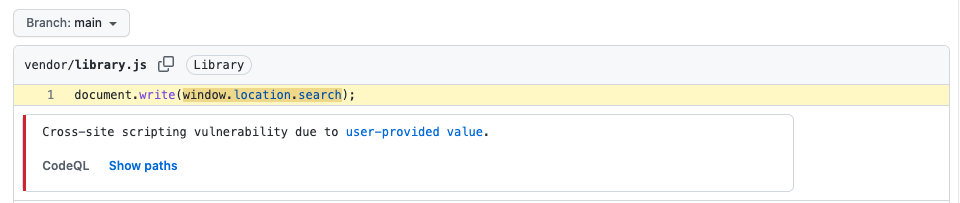
Im Folgenden siehst du ein Beispiel aus der Warnungsliste der code scanning, bei dem eine Warnung als in Bibliothekscode auftretend gekennzeichnet ist.

Auf der Warnungsseite kannst du sehen, dass der Dateipfad als Bibliothekscode gekennzeichnet ist (Kennzeichnung Library).
Informationen zu experimentellen Warnungen
Hinweis: Experimentelle Warnungen für code scanning werden mithilfe experimenteller Technologie in der Aktion CodeQL erstellt. Dieses Feature ist derzeit als Betarelease für JavaScript-Code verfügbar und kann noch geändert werden.
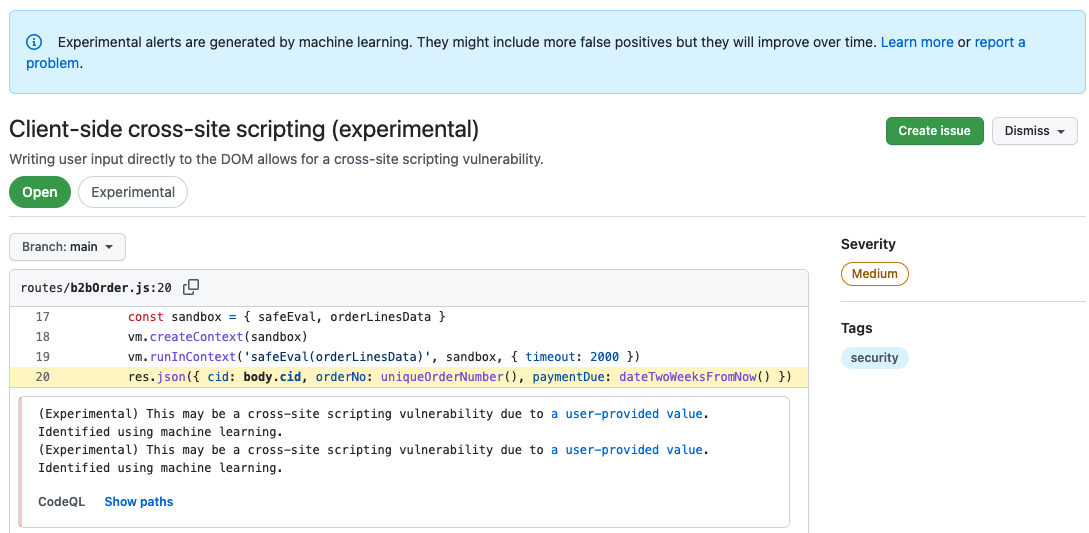
In Repositorys, die die code scanning mithilfe der CodeQL-Aktion ausführen, wirst du möglicherweise sehen, dass einige Warnungen als experimentell gekennzeichnet sind. Dies sind Warnungen, die mithilfe eines Machine Learning-Modells gefunden wurden, mit dem die Funktionen einer bestehenden CodeQL-Abfrage erweitert wurden.

Vorteile der Verwendung von Machine Learning-Modellen zum Erweitern von Abfragen
Abfragen, bei denen Machine Learning-Modelle verwendet werden, können Sicherheitsrisiken in Code finden, der mithilfe von Frameworks und Bibliotheken geschrieben wurde, die die Person, die die ursprüngliche Abfrage erstellt hat, in der Abfrage nicht berücksichtigt hat.
Alle Sicherheitsabfragen für CodeQL erkennen Code, der anfällig für eine bestimmte Art von Angriff ist. Die Abfragen werden von Sicherheitsforschern erstellt, die dabei die am häufigsten verwendeten Frameworks und Bibliotheken berücksichtigen. Daher findet jede vorhandene Abfrage Anwendungsfälle für häufig verwendete Frameworks und Bibliotheken, durch die Sicherheitsrisiken entstehen. Entwickler verwenden jedoch viele verschiedene Frameworks und Bibliotheken, und eine manuell verwaltete Abfrage kann nicht alle davon berücksichtigen. Daher decken manuell verwaltete Abfragen nicht alle Frameworks und Bibliotheken ab.
CodeQL verwendet ein Machine Learning-Modell, um eine vorhandene Sicherheitsabfrage zu erweitern, sodass eine größere Auswahl von Frameworks und Bibliotheken abgedeckt wird. Das Machine Learning-Modell wird darauf trainiert, Probleme in Code zu erkennen, der ihm noch nie zuvor begegnet ist. Abfragen, die das Modell verwenden, finden Ergebnisse für Frameworks und Bibliotheken, die in der ursprünglichen Abfrage nicht beschrieben werden.
Mithilfe von maschinellem Lernen gefundene Warnungen
Warnungen, die mithilfe eines Machine Learning-Modells gefunden wurden, werden als „Experimentelle Warnungen“ gekennzeichnet, um zu zeigen, dass diese Technologie sich derzeit in einer Phase der aktiven Entwicklung befindet. Bei diesen Warnungen gibt es eine höhere Rate falsch positiver Ergebnisse als bei den Abfragen, auf denen sie basieren. Das Machine Learning-Modell verbessert sich durch Benutzeraktionen wie das Kennzeichnen eines schlechten Ergebnisses als False Positive oder das Beheben eines Problems aus einem guten Ergebnis.
Aktivieren von experimentellen Warnungen
Die CodeQL-Standardabfragesammlungen enthalten keine Abfragen, die maschinelles Lernen zum Generieren experimenteller Warnungen verwenden. Damit während der code scanning Machine-Learning-Abfragen ausgeführt werden, musst du die zusätzlichen Abfragen in einer der folgenden Abfragesammlungen ausführen.
| Abfrageauflistung | Beschreibung |
|---|---|
security-extended | Abfragen aus der Standardsammlung sowie Abfragen zu niedrigeren Schweregraden und Genauigkeit |
security-and-quality | Abfragen von security-extended, sowie zusätzliche Abfragen zur Verwaltbarkeit und Zuverlässigkeit |
Wenn du deinen Workflow so aktualisierst, dass eine zusätzliche Abfragesammlung ausgeführt wird, erhöht sich die Analysezeit.
- uses: github/codeql-action/init@v2
with:
# Run extended queries including queries using machine learning
queries: security-extended
Weitere Informationen findest du unter Anpassen der code scanning.
Deaktivieren von experimentellen Warnungen
Die einfachste Möglichkeit, Abfragen zu deaktivieren, die maschinelles Lernen zum Generieren experimenteller Warnungen verwenden, besteht darin, das Ausführen der Abfragesammlung security-extended oder security-and-quality zu beenden. Im obigen Beispiel würdest du hierfür die queries-Zeile auskommentieren. Wenn du die Sammlung security-extended oder security-and-quality weiterhin ausführen musst und die Machine-Learning-Abfragen Probleme verursachen, kannst du ein Ticket mit den folgenden Angaben an den GitHub-Support senden.
- Tickettitel: „code scanning: Entfernen aus der Betaversion für experimentelle Warnungen“
- Gib ausführliche Informationen zu den betroffenen Repositorys oder Organisationen an.
- Beantrage eine Eskalation an das Entwicklungsteam.